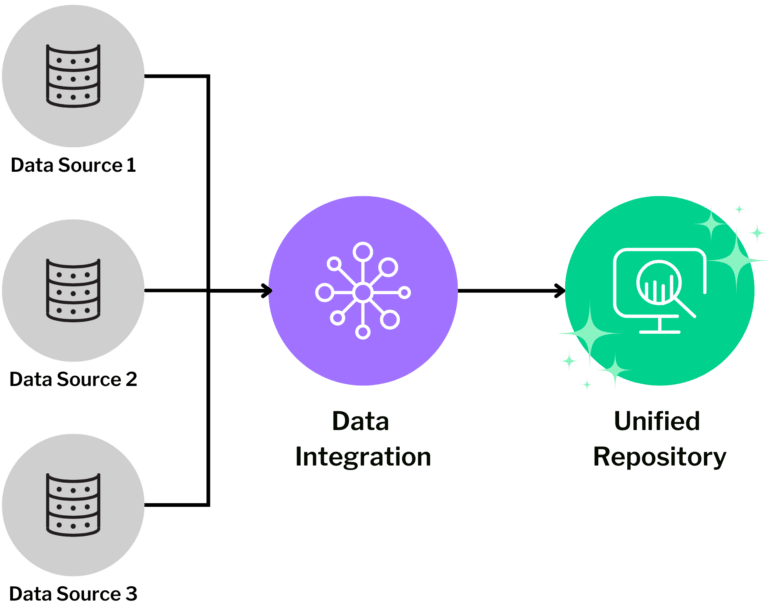
Smarter Forecasting: How ML is Redefining Demand Prediction
Written by
Jacob Dink, AI/ML Director
Published
January 23, 2025

Customers today are faced with more choices than ever, prompting businesses to step up their game in a fiercely competitive global market. To thrive, companies must not only provide exceptional value but also anticipate customer demand effectively. Traditional forecasting methods, which often rely heavily on historical data, can hinder growth and scalability.
This is where machine learning-powered demand forecasting and inventory optimization come into play. These advanced techniques enable businesses to predict demand accurately, allocate resources efficiently, adapt to market fluctuations, and foster long-term customer loyalty.
In this post, we’ll explore how leveraging demand forecasting and inventory optimization can streamline operations and why these strategies are essential for any modern business.
How Can Forecasting Unlock Business Agility and Accuracy?
Businesses need to stay ahead of shifting demands and unpredictable market changes. Demand forecasting and optimization empower organizations to predict future needs, align resources, and respond with confidence to evolving conditions.
Leveraging advanced analytics and AI-driven insights can help businesses sift through vast volumes of data, and make the most of the following multifaceted benefits:
- Enabled Smarter Decisions: Leverage accurate demand forecasts to inform decisions about inventory, staffing, and production, reducing waste and optimizing resources.
- Improved Agility: Use predictive models and optimization techniques to quickly adapt to market shifts, seasonal trends, and unexpected disruptions.
- Cost Savings: Align supply with demand and streamline your manufacturing processes to minimize overstock and stockouts, enhance operational efficiency, and reduce carrying costs.
- Enhanced Customer Satisfaction: Analyze massive datasets to meet customer demand with precision, improve fulfillment rates, and enhance customer experiences, fostering loyalty and trust.
- Data-Driven Strategies: Utilize historical data and AI-driven insights to forecast future trends with accuracy, and gain a competitive edge in your industry.
Which Machine Learning Approaches Can You Use for Demand Forecasting?
Time-Series Forecasting
Time-series forecasting analyzes sequential historical data to predict future values. Techniques such as Autoregressive Integrated Moving Average (ARIMA) and exponential smoothing are commonly used to identify patterns like trends and seasonality, enabling businesses to anticipate demand fluctuations over time.
By integrating machine learning with time-series analysis, businesses can make informed decisions on inventory management and pricing strategies, ultimately reducing costs associated with overstocking or stockouts.
Regression Analysis
Regression models predict a continuous dependent variable, such as sales volume, based on one or more independent variables, like price or marketing spend.
These models enable businesses to quantify relationships between variables, helping them understand how different factors influence demand and make informed decisions accordingly.
Regression analysis can be enhanced and made more robust and adaptable through the following machine learning techniques:
- Supervised Learning Framework: Regression falls under supervised learning, where models are trained on historical data to predict future outcomes. This involves splitting the dataset into training and testing sets to evaluate model performance.
- Feature Engineering: Feature engineering plays a crucial role in creating new input features based on existing data and improving model accuracy. For instance, creating interaction terms between independent variables can capture complex relationships.
- Algorithm Selection and Optimization: Algorithms such as decision trees and support vector machines can be utilized alongside traditional regression techniques to enhance predictive power. Automated machine learning (AutoML) platforms can streamline this process by optimizing model selection and hyperparameter tuning.
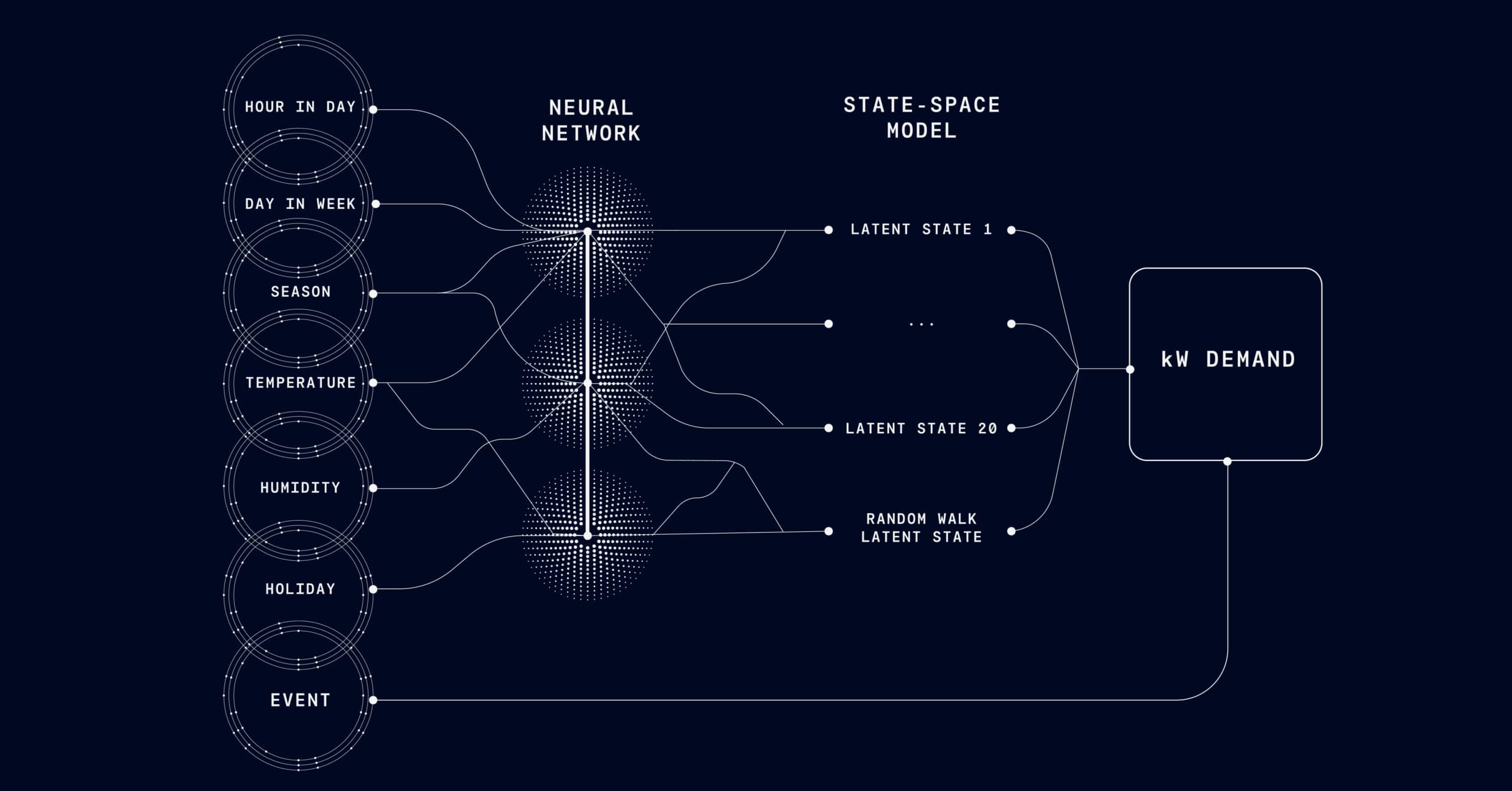
Neural Networks
Neural networks, particularly deep learning models, can identify complex, non-linear patterns and relationships within data. They can model intricate interactions between variables, making them powerful tools for capturing the multifaceted nature of demand influences.
What’s more, neural networks accurately model complex relationships within the data, enabling them to significantly outperform traditional forecasting methods.
For companies with large datasets across various regions and products, neural networks—such as long short-term memory (LSTM) networks and recurrent neural networks (RNNs)—can improve forecast accuracy and streamline inventory management.
Reinforcement Learning
Reinforcement Learning lets you make sequential decisions that maximize a long-term reward. In demand forecasting, this approach helps you continuously learn from outcomes and optimize strategies thereby improving decision-making processes over time.
Additionally, Reinforcement Learning is an approach that can help you:
- Adjust prices in real-time based on predicted demand fluctuations and competitor actions.
- Predict future demand to optimize inventory levels and determine the best restocking strategies.
- Forecast the impact of promotional activities on demand to identify the most effective campaigns.
- Enhance supply chain operations and ensure that they meet customer demands efficiently while minimizing costs.
Bayesian Analysis
Bayesian models incorporate prior knowledge and update predictions as new data becomes available to estimate the likelihood of various outcomes. This dynamic and flexible forecasting approach operates on the principle of updating beliefs about uncertain parameters through Bayes’ theorem.
Unlike traditional forecasting methods, Bayesian models produce a distribution of possible outcomes and enable businesses to understand the range of potential future demands and the associated risks.
In industries with intermittent demand patterns, Bayesian methods can effectively combine historical knowledge with sparsely observed data to estimate future needs thereby improving inventory management.
Hierarchical Forecasting
Hierarchical forecasting is used in scenarios with nested time series that together add up to a coherent whole. For instance, predicting sales at a national level can be broken down into regions, stores, and individual products. This method ensures consistency across different aggregation levels and leverages data from various hierarchy levels to improve accuracy.
In energy management, hierarchical forecasting can predict consumption patterns across different sources (e.g., solar, wind) and geographical areas, facilitating better grid management and resource allocation.
Forecasting patient admissions or medical supply needs across hospitals and regions is another application where hierarchical forecasting provides consistency across levels.
Multivariate Forecasting
In multivariate forecasting, multiple related time series are modeled together to capture the relationships between them. For instance, forecasting the demand for related product lines simultaneously can provide insights that improve the accuracy of each forecast by considering the interplay between products.
The multivariate forecasting approach also incorporates factors such as promotional activities, competitor pricing, and economic indicators to enable retail and sales forecasting. Moreover, this method considers lead times, supplier reliability, and market trends to optimize inventory levels and production schedules.
As organizations seek data-driven insights for decision-making, implementing multivariate forecasting will be essential for optimizing operations and enhancing competitiveness in dynamic markets.
Hybrid Forecasting
Hybrid forecasting combines multiple forecasting methods to leverage the strengths of each. Integrating different models enables businesses to achieve more robust and accurate predictions, accommodate various data patterns, and mitigate the limitations inherent in single-method approaches.
Retailers can combine historical sales data with promotions, and seasonality, to predict sales.
In healthcare, hybrid forecasting integrates historical usage data with factors such as seasonal illness patterns and demographic changes to optimize inventory levels for medical supplies.
For instance, a hybrid model can use the Autoregressive Integrated Moving Average (ARIMA) method to identify trends while also using a neural network to understand complex, non-linear influences, such as the effects of marketing campaigns.
Key Takeaways
Mastering customer demand is no easy feat—it requires precision, insight, and adaptability.
Demand forecasters harness a range of tools, from time series analysis to advanced machine learning models, unlocking unparalleled accuracy and transforming raw data into actionable insights. These innovations empower businesses to not only analyze the resources available but also anticipate customer expectations in the future with confidence.
By adopting demand forecasting and optimization strategies, organizations can thrive in the present and scale and innovate for the future leading to:
- Improved forecast accuracy
- Significant cost savings
- Enhanced efficiency
- Scalability and agility
Get Started
Stay ahead in today’s dynamic market by leveraging cutting-edge demand forecasting models and optimization strategies. We're here to help you build the strategy and technology you need to tackle your business challenges.
Contact Us